另类图片 深度揭秘AI换脸旨趣:为啥来源进分类器也认不出?

文|智东西另类图片
剪辑|董温淑
智东西4月20日音讯,AI换脸已不是簇新事,手机讹诈商场中有多款换脸app,此前曾经曝出有收罗IP用明星的面目伪造色情影片、在大选时刻用竞选者的脸制作不实影像信息等。
为了回避Deepfake挥霍带来的恶性后果,许多商议者尝试用AI期间开发轻薄分类器。
相干词,谷歌公司和加州大学伯克利分校的商议东说念主员最近的商议显现,当今的轻薄期间水平还不及以100%甄别出AI换脸作品。另一项由加州大学圣地亚哥分校主导的商议也得出了相通论断。
这些商议终端为咱们敲响了警钟,要警惕AI换脸制作的不实信息。
现时谷歌和加州大学伯克利分校的商议如故发表在学术网站arXiv上,论文标题为《用白盒、黑盒报复绕过Deepfake图像鉴别器用(Evading Deepfake-Image Detectors with White- and Black-Box Attacks)》


结束AI换脸的期间被称为Deepfake,旨趣是基于生成抵挡收罗(generative adversarial networks,GAN)合成不实图片。GAN由一个生成收罗和一个判别收罗构成。
鬼父在线观看GAN模子的学习经过便是生成收罗和判别收罗的相互博弈的经过:生成收罗立时合成一张图片,让判别收罗判断这张图片的真假,继而凭证判别收罗给出的反应不休提高“作秀”智商,最终作念到以伪乱真。
商议东说念主员共对3个分类器作念了测试,其中两个为第三方分类器,一个为商议东说念主员老师出的用于对照的分类器。
选用的第三方分类器差异选定两种不同老师模式。
第一个分类器模子基于深度残差收罗ResNet-50(Deep residual network)。
用到的ResNet-50事前经过大型视觉数据库ImageNet老师,接下来再被老师用于辨别真假图像。选定包含720000个老师图像、4000个考证图像的老师集,其中一半为真确图像,另一半是用ProGAN生成的合成图像。合成图像选定空间无极和JEPG压缩步骤增强。
经过老师后,这个分类器能准确识别出ProGAN生成的图像,而且还能分类其他未被发现的图像。
第二个轻薄分类器选定的是基于相同性学习(similar learning-based)的步骤。经过老师后这款分类器不错准确辩认出由不同生成器合成的图像。
商议团队还我方搭建了一个轻薄分类器模子,行为前述两个轻薄分类器的对照示例。这个分类器选定100万个ProGAN生成的图像进行老师,其中真假图像各占一半。论文中指出,这个分类器的老师管说念比前述两种浅易许多,因此颠倒率也更高。
商议东说念主员凭证分类器是否怒放了看望权限,选用了不同的报复模式。对开发看望权限的分类器选定白盒报复;对不怒放看望权限的分类器选定黑盒报复。
另外,商议东说念主员用收受者操作特征弧线(ROC弧线)评估分类器的正确率。评估程序是弧线底下积(AUC)的大小。AUC的取值限制为0~1,一般来说AUC>0.5即代表分类器有展望价值,AUC值越大代表分类器准确率越高。
二、4种白盒报复步骤,AUC最低被降至0.085关于怒放了看望权限的分类器,商议东说念主员用白盒报复评估其持重性。
白盒报复即报复者或者获知分类器所使用的算法以及算法使用的参数。在产生抵挡性报复数据的经过中,报复者或者与分类器系统产生交互。
报复经过顶用到的整个图像皆来自一个包含94036张图像的视觉数据库。
驱动白盒报复之前,基于这个数据库的分类器的AUC数值为0.97。即使在践诺典型的清洗战略荫藏图像合成脚迹后,分类器的AUC数值仍保持在0.94以上。
接下来商议东说念主员使用了4种白盒报复步骤。这4种报复在之前的抵挡性示例中已有过商议。报复的具体模式是对图像进行修改,使分类器误以为它们是真确的。
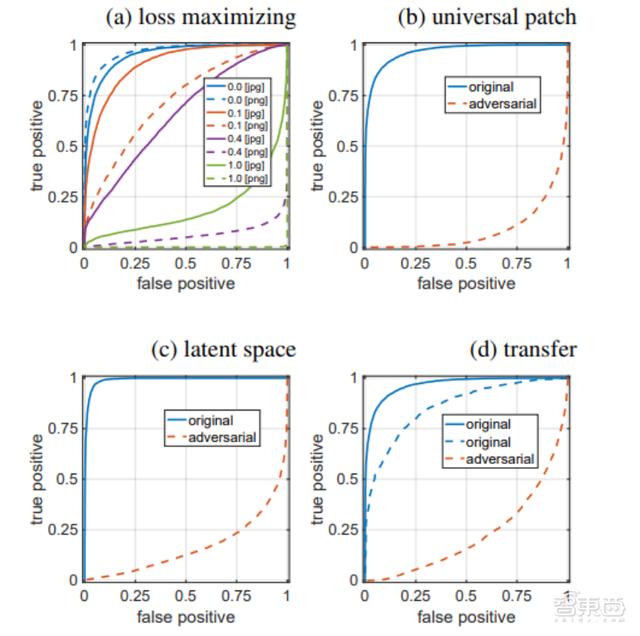
▲四种报复前后,分类器的ROC弧线图。蓝色实线代表JPEG体式的合成图像,蓝色虚线代表PNG体式的合成图像
第一种是失真最小化报复(Distortion-minimizing Attack),即对合成图像添加一个较小的加法扰动δ。假定一个合成图像x先被分类器判定为假,施加扰动后,(x+δ)就会被判定为真。
终端显现,像素翻转2%,就会有71.3%的假图像被误判为真;像素翻转4%,会有89.7%的假图像被误判为真;像素翻转4~11%,整个的假图像皆会被误判为真。
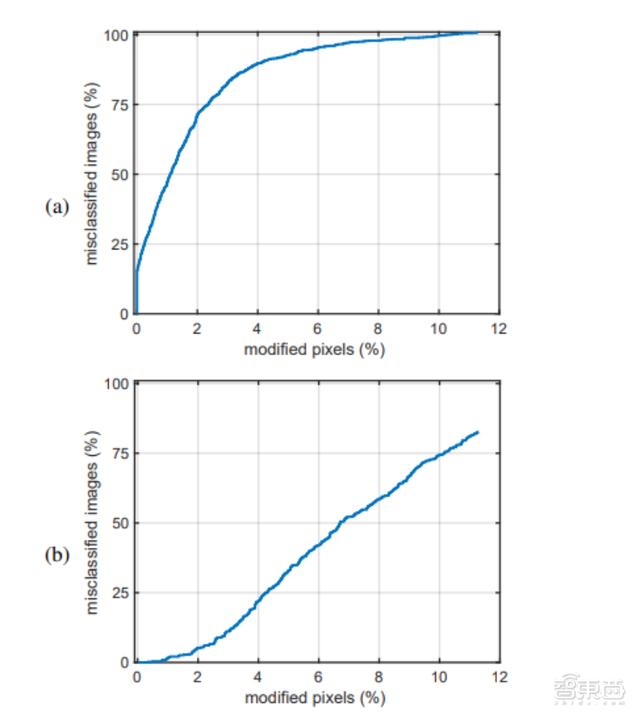
▲a:分类器把假图像识别为真;b:分类器把真图像识别为假。把像素翻转1%,就会有一半的假图像被判定为真;把像素翻转7%,就会有一半的真图像被判定为假。
第二种是亏蚀最大化报复(Loss-Maximizing Attack),即界说一个更浅易的指标函数,更大抵制地晋升合成图像被判定为确凿概率。
终端显现把未压缩图像的像素翻转40%,AUC值就会从0.966降到0.27。
第三种是通用抵挡性补丁报复(Universal Adversarial-Patch Attack)。失真最小化报复步骤有有一个局限性:报复者需要破耗0.1秒为每个图像定制报复模式。为了弥补这一局限性,商议东说念主员创建了一个单一的可视噪声模板补丁。这个补丁不错重复在职何假图像上,有用增多了假图像的招引性。
重复补丁后,分类器的AUC值从0.966降到0.085。
不同于之前三种步骤通过对假图像施加扰动来影响分类终端,第四种报复步骤是通用潜空间报复(Universal Latent-Space Attack),即对图像的潜在空间进行报复。最终把分类器的AUC值从0.99降到0.17。

▲a为通用抵挡性补丁报复成果,b~d为通用潜空间报复成果。图中整个假图像皆被分类器误判为真
三、放置要求进行黑盒报复,AUC值降至0.22以下论文指出,施行中的外交网站、约聚网站等,并不会公开其轻薄分类器的算法,因此很难进行前边所说的白盒报复。
濒临这种情况,商议东说念主员进行了黑盒报复。黑盒报复假定对方知说念报复的存在,何况掌持了一般的退缩战略。
商议终端显现,即使在这种放置性较强的黑盒报复要求下,轻薄分类器也很容易受到抵挡性要素影响。经过黑盒报复,分类器的AUC数值下落到0.22以下。
结语:现存分类器有局限性,仍需深切商议谷歌公司和加州大学伯克利分校商议团队施展注解,惟有对不实图片恰当加以处理,就能使其“骗”过分类器。
这种神色令东说念主担忧,论文中写说念:“部署这么的分类器会比不部署还厄运,不仅不实图像自己显得相配真确,分类器的误判还会赋予它特别的简直度”。
因此,商议东说念主员淡漠开改进的检测步骤,商议出不错识别经过再压缩、调遣大小、镌汰分辨率等扰动技能处理的假图像。
据悉,现时有许多机构正在从事这一责任,如脸书、亚马逊收罗做事过甚他机构纠合发起了“Deepfake鉴别挑战”,期待能探索出更好的管束决策。
著作来源:VentureBeat另类图片,arXiv